Para nós que cuidamos muitas vezes da infraestrutura dos servidores sabemos a importância de performance em nossos processos executados principalmente em produção, e esse cuidado se torna em vício real
É bem natural que qualquer pessoa que seja dessa parte de infraestrutura em geral seja viciado loucamente em performance e baixo consumo de hardware, por mais parruda que seja a aplicação sobrar nunca é demais

Treta
O shell é a coisa mais linda que temos nessa porra de vida, e como a nossa vida existem várias formas de fazer a mesma coisa, só que uma delas dificilmente dão o mesmo resultado na questão de performance, isso é claro né?!
E não diferentemente disso acontece com o echo, temos algumas alternativas como por exemplo a que chamamos de here-document (<<) usada no cat (para sair no STDOU) e também o printf que tem uma sintaxe bem parecida com a do echo e ainda também fiz com o printf com here-document direcionando a /dev/stdout.
E como qualquer viciado fiquei curioso em saber se eles se diferenciavam em performance nem que seja questão de milissegundos, e sei que você só está lendo esse artigo porque também é um viciado como eu 💀.
ANALISANDO
A forma que achei mais style fodastica foi usando o here-document do cat, mano cola só na sintaxe:
Mas deixei pra lá o meu style super hacker fodão e me liguei na performance, então obviamente ele foi o primeiro que eu teste, usando o strace pude mapear as requisições feitas ao executar aquele código e tive uma saída um pouco verbosa, mas estudaremos as saídas quando formos comparar os diferentes métodos.
Mas deixando de conversa mole vamos as paradas, primeiramente vamos aos testes.
Outra forma de testar foi usando o printf e apontando para escrever em /dev/stdout que é um link simbólico que aponta para outro link simbólico que aponta para outro, ele tem tantos links assim pelo simples motivo de identificar qual a TTY logada e coisas do tipo, o segundo link se localiza em /proc/self/fd/1 e o primeiro no meu caso estava dentro de /dev/pts/0.
AOS TESTES
Com minha duvida do caralho eu fiz um script afim de medir a porra dessa velocidade, e saber qual na prática era que iria executar mais rápido, e até que fim pude descobrir, meu teste foi simples, baseado em quatro funções onde elas exibiam 10000 vezes uma série de caracteres randômicos ("@#$%%&*I&FDFSRWEGsy€®³®ŧŋđðđðŋæ") e sem quebra de linhas ou espaços e nem tabs.
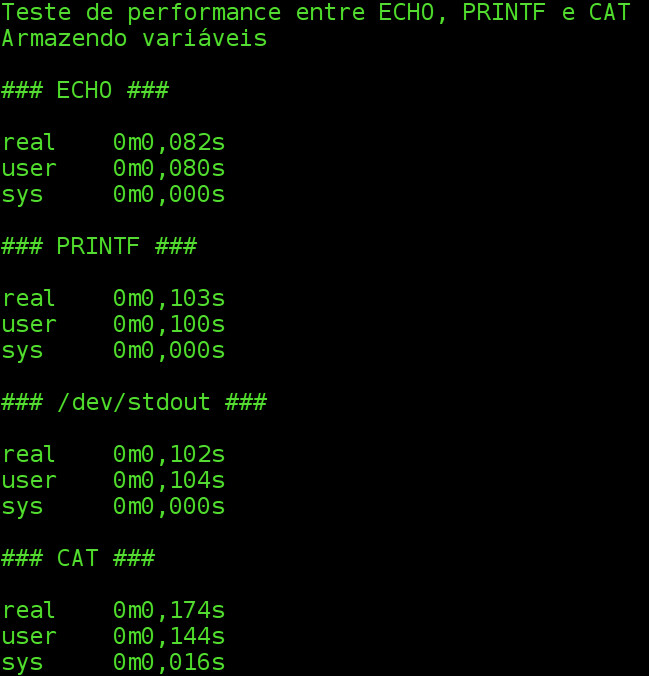
Na saída acima vemos que o echo foi mais rápido em questão de milessegundos, e o printf direcionando para o stdout foi o segundo mais veloz, com 0,102s, o printf ficou em terceiro lugar por 1 ms e o cat usando here-document ficou com a pior performance com 0,174s.

CAT (da morte)
O cat na prática e após ser executado cria um espaço dinâmico na memória para a alocação, e pra isso é necessário ela chamar também um descritor de arquivo fd (file descriptor) e saber o estado do arquivo, se existe ou se pode ou nao pode ser lido, conforme estão no padrão do módulo do libc unistd.h pode ser encontrado em /usr/include/unistd.h definindo: STDIN_FILENO, STDOUT_FILENO e STDERR_FILENO, que é respectivamente o número 1, 2 e 3.
Outra forma que colabora para que sua execução venha demorar mais é a função read(), para que ele imprima é necessário que tenham entrada de dados, e o cat não armazenou a entrada, a única que ele armazenou foi o primeiro argumento no qual foi ignorado por não ser um arquivo, e esse passo faz com que ela receba armazene em uma variável, e é aqui que a porca torce o rabo!

Se você executar strace cat, ele irá parar e esperar uma entrada em read(0, e após a entrada ele executa o script normalmente.
Esses passos fazem com que ele perca o tempo suficiente para que tenha uma maior demanda de tempo e aumenta o tempo de sua execução.
Printf VS Echo
Em nosso exemplo foi feito um teste de explosão de carácteres em cada função e foi analisada a performance, ok... Mas e se nós tentássemos criar um script que executaria cada função por várias vezes?
Como assim?
Se nós escrevermos um laço de repetição pra cada função de impressão na tela poderemos verificar qual o mais performático em uma perspectiva de varias vezes no código ser chamada a mesma função.
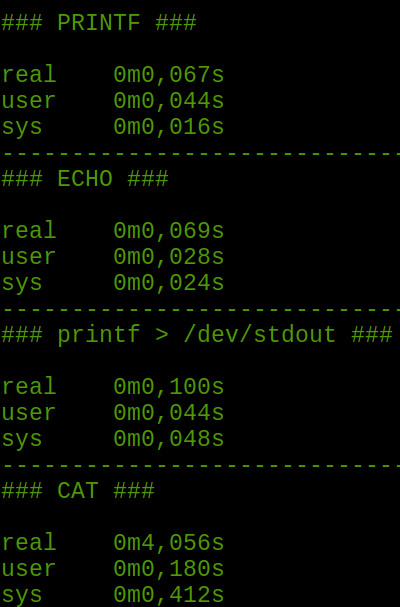
Notei que diferentes vezes que eu realizava o mesmo teste o resultado do echo era mais rápido e outros mais lento do que o da função no printf, isso me incomodou bastante, mas se notarmos o embora o resultado seja diferente, as duas funções na prática são muito semelhantes, mas existem algumas diferenças que acho interessante detalhar.
Estudando o fruto desde a raiz
As duas funções são de cara executadas pelo bash e de lá é direcionado a abrir um outro binário que é o correspondente que no caso é o echo e o printf elas duas são invocadas de /usr/bin/binário e é feita toda a alocação, definição de leitura e armazenamento de "arquivo" (como é tratado qualquer coisa nos Unix-likes), em um determinado momento que está tudo certo ele chega a criar o arquivo virtual para direcionar ao STDOUT (já citado anteriormente) e em que a nível de sistema ele chama a função fstat do módulo C stat (que pode ser encontrado em /usr/include/(plataforma)-linux-gnu/sys/stat.h) em que é alogo como fstat(1, {st_mode=S_IFCHR|0620 ..., o st_mode é o valor de configuração que seta qual será o tipo de arquivo a ser retornado, e a opção preenchida foi S_IFCHR que é significa que o arquivo é de caracteres especiais, e seguido isso usa-se um pipe ("|" Essse símbolo) no trecho mostra 0620 que se refere a permissão de arquivo, no caso ele não terá permissão especial (stickbit, suid nem sgid) o usuário dono do arquivo poderá escrever e ler e o grupo do usuário poderá apenas escrever naquele arquvo que você pôs como entrada na função, de modo legível a permissão seria wr- w-- ---.
E como segundo argumento encapsulado, temos st_rdev=makedev(136, 2), o st_rdev é uma variável de configuração de Device ID (identifica se o arquivo é caractere ou bloco especial), essa variável retorna um valor inteiro, e passam dois argumentos, sendo o primeiro o identificador Device ID e nomeado de Major e o segundo é o identificador da instância específica do Device ID esses dois argumentos parecem confusos mas assim essa função faz como o mknod, onde é criado um arquivo de relação de kernel no diretório /dev/.
A criação de um arquivo especial do tipo: bloco, FIFO e caracter. É totalmente util para o menor consumo de dados no armazenamento do mesmo, já que o arquivo se sobreescreve e não mantém sempre aumentando o conteúdo a cada alteração, além de que o arquivo em sí é salvo como o arquivo que estamos estudando agora, na prática ele é salvo em um estado de condenação após execução e quase impossível se quer notar alguma alteração no sistema.
Após estudar todos esses padrões que coincidem entre os dois programas, notamos a total e unica diferença quase que insignificante na função que é chamada abaixo, a write (Módulo pode ser encontrado em /usr/include/unistd.h), em nosso trecho de teste podemos pegar write(1, "trecho de teste\n", 16trecho de teste), sendo usada a função principal afim da execução, a função write tem três argumentos, sendo o primeiro o __fd(File descriptor) comentado já anteriormente, o segundo o texto, chamado de __buf e o terceiro e ultimo sendo um valor inteiro da quantidade de bytes, chamada de __nbyte. no caso do echo ele acrescenta apenas 1 byte a mais, que é a quebra de linha \n (que é identificado como 10 em ascii), já o printf apenas imprime o texto passado, sem que haja quebra de linha e assim faz com que seja "mais veloz", a diferença é tão detalhista que nem se quer um teste bem projetado poderia medir, tendo em vista que após calcular e terminar o primeiro procedimento o processador já estará quente, ou já teria armazenado dados a mais, também considerando a temperatura local, a corrente de vento e por mínimo que seja a mudança ela surtará efeito no conometro.
Conclusão
Sendo isso é possível notar que o printf saiu mais veloz em varias chamadas repetidas, e o echo se saiu mais veloz em apenas uma chamada de uma vez, mesmo não havendo diferenças relevantes entre as duas. Faça você mesmo teste em sua plataforma, verifique você mesmo, as vezes nem sempre o printf será aconselhado, já que pode ser usado o echo e ele já terminará em uma quebra de linha, sem precisar de que digite o \n, além de tudo isso os comandos com formatação e coloração, são todos suportados por padrão no printf (tanto no bash quanto no C, que também pode ser usado o write, o que seria mais low-level), já o echo precisaria passar o parâmetro -e.
Dada as métricas, cabe a você estudar a sua situação e verificar qual o que melhor se encaixa para seu ambiente, sabemos que 1 ms faz toda a diferença em nossos servidores :)